This Week in AI: weekly AI Updates

Neha
February 16, 2024

This week in artificial intelligence, we have witnessed groundbreaking advancements that promise to change technology, creativity, human life, and machine understanding. From Google’s latest model, Gemini 1.5, to the innovative video generation capabilities of Sora, and the unveiling of V-JEPA and I-JEPA by Meta, the field of AI is advancing at an unprecedented pace, pushing beyond what was once thought to be unimaginable. These updates and explore what they mean for the future of AI.

Google and Alphabet CEO Sundar Pichai announced the rollout of Gemini 1.5, a successor to the highly capable Gemini 1.0 Ultra. This new generation model showcases dramatic improvements in efficiency and capability, particularly in long-context understanding, with a capacity to process up to 1 million tokens. This breakthrough extends the potential for developers and enterprises to build more complex and nuanced AI applications, promising a future where AI’s understanding and interaction with human language are deeper and more meaningful than ever before.
The introduction of Sora marks a significant milestone in video generation technology. By training on a diverse array of videos and images, Sora can generate high-fidelity videos up to a minute long, showcasing an unprecedented level of detail and realism. This model’s ability to simulate the physical world opens up new possibilities for content creation, education, and entertainment, offering a glimpse into a future where AI-generated content is indistinguishable from reality.
Sora represents a significant leap in AI’s ability to generate video content. At its core, Sora is a text-conditional diffusion model that operates on a novel principle of transforming videos and images into a unified representation for large-scale training. This approach enables the generation of high-fidelity videos of variable durations, resolutions, and aspect ratios. Here’s a closer look at the mechanics behind Sora:

Sora begins by compressing visual data (videos and images) into a lower-dimensional latent space. This process involves reducing the dimensionality of the visual content temporally (over time) and spatially (across the image or video frame). Once compressed, the data is decomposed into spacetime patches, which serve as the basic units for the model’s training and generation processes.
These patches act as tokens for the transformer architecture, similar to how words or subwords function in language models. By creating videos as sequences of these spacetime patches, Sora can efficiently learn from and generate content across a wide range of visual formats.
Sora employs a diffusion transformer architecture, which has shown remarkable scaling properties in various domains. In the context of video generation, the model is trained to predict the original “clean” patches from noisy input patches, conditioned on textual or other forms of prompts. This process iteratively refines the generated content, leading to high-quality video outputs.
One of the key strengths of Sora is its flexibility in generating content. By arranging randomly-initialized patches in grids of different sizes, Sora can produce videos and images tailored to specific resolutions, durations, and aspect ratios. This capability allows for a wide range of creative and practical applications, from generating content for different screen sizes to simulating complex visual scenarios.
Meta’s release of the Video Joint Embedding Predictive Architecture (V-JEPA) model represents a significant step towards realising Yann LeCun’s vision of advanced machine intelligence (AMI). V-JEPA’s approach to understanding the world through video analysis could revolutionise how machines learn from and interact with their environment, paving the way for more intuitive and human-like AI systems.
The Video Joint Embedding Predictive Architecture (V-JEPA) is a groundbreaking model developed by Meta, aimed at advancing machine intelligence through a more nuanced understanding of video content. Unlike traditional models that focus on generating or classifying pixel-level data, V-JEPA operates at a higher level of abstraction. Here’s an overview of how V-JEPA functions:

At its core, V-JEPA is designed to predict missing or masked parts of videos. However, instead of focusing on the pixel level, it predicts these missing parts in an abstract representation space. This approach allows the model to concentrate on the conceptual and contextual information contained within the video, rather than getting bogged down by the minutiae of visual details.
V-JEPA employs a self-supervised learning strategy, where a significant portion of the video data is masked out during training. The model is then tasked with predicting the content of these masked regions, not by reconstructing the exact visual details, but by understanding and generating abstract representations of what those regions contain. This method encourages the model to learn higher-level concepts and dynamics of the visual world.

One of the innovative aspects of V-JEPA is its efficiency in learning from video data. By focusing on abstract representations, the model achieves significant gains in training and sample efficiency. Furthermore, V-JEPA’s architecture allows it to be adapted to various tasks without the need for extensive retraining. Instead, small, task-specific layers or networks can be trained on top of the pre-trained model, enabling rapid deployment to new applications.
V-JEPA’s masking strategy is carefully designed to challenge the model sufficiently, forcing it to develop a deeper understanding of video content. By masking out large regions of the video both in space and time, the model must learn to infer not just the immediate next frame but the overall dynamics and interactions within the scene. This approach helps V-JEPA develop a more grounded understanding of the physical world, much like how humans learn from observing their environment.
The artificial intelligence (AI) showcased this week includes some truly amazing developments that point to a bright future for innovation. From Google’s Gemini 1.5 to Meta’s V-JEPA, these technologies are pushing the limits of what AI can accomplish, promising improved understanding, increased creativity, and more human-like interactions. These innovations have the potential to transform many industries and help shape a future in which AI plays an increasingly important role in our lives as it develops.

TL;DR Claude Fable 5 launched on June 9, 2026, was pulled offline three days later under a US export control order, and returned on July 1 after the order was lifted. For support teams, Fable 5 is best suited for long-horizon tickets across billing, CRM, shipping, and documents not basic FAQ deflection. Its biggest support […]


At YourGPT, we’ve always believed businesses need one platform for customer support, sales, and engagement. These are not separate parts of the customer journey. They shape how businesses communicate, build relationships, and move conversations forward. That belief continues to guide how we evolve YourGPT, building toward a more connected way for teams to manage communication, […]
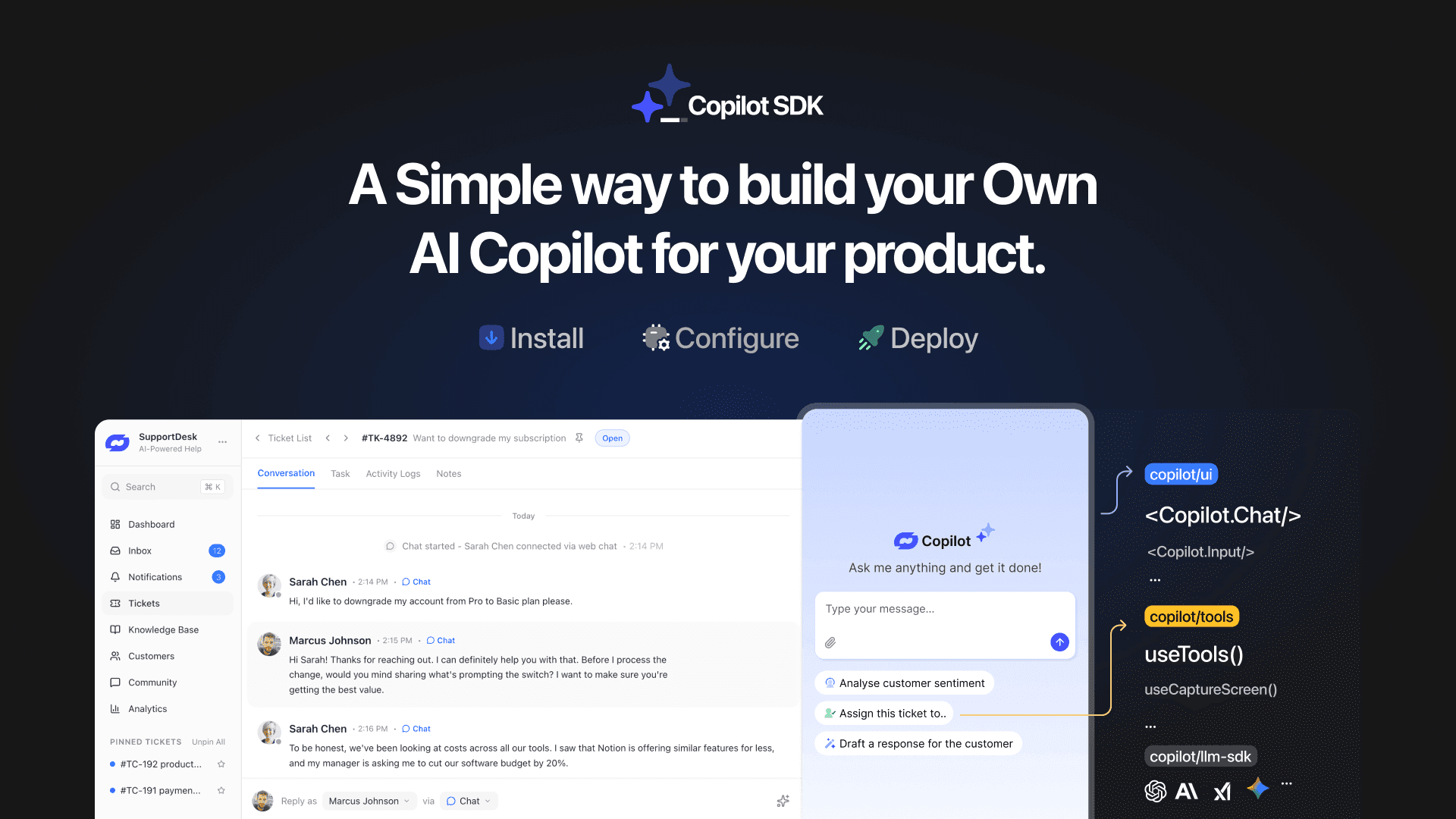
TL;DR YourGPT Copilot SDK is an open-source SDK for building AI agents that understand application state and can take real actions inside your product. Instead of isolated chat widgets, these agents are connected to your product, understand what users are doing, and have full context. This allows teams to build AI that executes tasks directly […]

Happy New Year! We hope 2026 brings you closer to everything you’re working toward. Throughout 2025, you’ve seen the platform evolve. We shipped the AI Copilot Builder so your AI could execute actions on both frontend and backend, not just answer questions. We added AI assistance inside Studio to help you generate workflows without starting […]

Grok 4 is xAI’s most advanced large language model, representing a step change from Grok 3. With a 130K+ context window, built-in coding support, and multimodal capabilities, Grok 4 is designed for users who demand both reasoning and performance. If you’re wondering what Grok 4 offers, how it differs from previous versions, and how you […]

OpenAI officially launched GPT-5 on August 7, 2025 during a livestream event, marking one of the most significant AI releases since GPT-4. This unified system combines advanced reasoning capabilities with multimodal processing and introduces a companion family of open-weight models called GPT-OSS. If you are evaluating GPT-5 for your business, comparing it to GPT-4.1, or […]