The 2026 AI Agent Playbook: Evaluating Support and Sales

Rajni
March 18, 2026

Most AI agent platforms look strong in demos but fail in production due to weak integrations, poor data grounding, and missing guardrails. Evaluate based on execution, not conversation. Test with real data using a golden question set. Verify action capability, integrations, and escalation quality. Measure outcomes like resolution rate, not demo performance.
AI adoption is accelerating across industries, but production success tells a different story. Many platforms look convincing in demos, yet fail when exposed to real workflows. This guide provides a practical framework to evaluate AI agent platforms before you commit.
In 2026, nearly every vendor claims their platform can transform customer support, automate sales pipelines, and improve operations. Those claims often hold in controlled environments. The gap appears when these systems interact with real customers, inconsistent CRM data, and unpredictable edge cases. By that point, the decision is already locked in.
The shift is clear. This is no longer about chatbots that answer questions. It is about AI agents that take action, update systems, and complete tasks with measurable business impact. That shift demands a different evaluation approach.
This blog explains how to assess AI agent platforms across support, sales, and operations, what separates reliable systems from fragile ones in production, and the checklist to apply before making a decision.
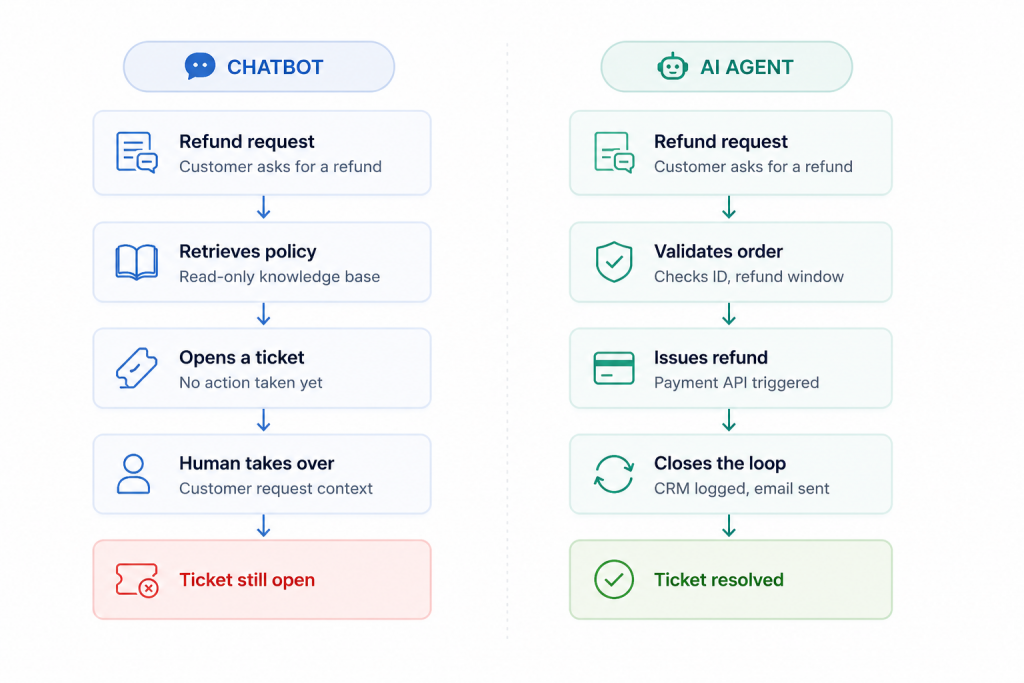
Before evaluating platforms, it is worth being precise about what you are actually buying. There is a significant difference between a chatbot and an AI agent, and conflating the two leads to wrong purchasing decisions and misaligned expectations.
A chatbot is a conversational interface that retrieves and presents information. It answers questions, surfaces knowledge base articles, and routes conversations. It reacts to what a user says. An AI agent goes further: it understands the user’s intent, decides what to do about it, and executes a sequence of actions across connected systems without requiring a human to act on its output.
Consider a customer asking for a refund. A chatbot tells the customer what the refund policy is and maybe creates a ticket. An AI agent validates the order ID against your order management system, checks whether the purchase falls within the refund window, confirms the customer’s payment method, triggers the refund through your payment processor, logs the action in your CRM, and sends a confirmation email. The ticket is closed, not just opened.
That distinction matters for every use case. In customer support, AI agents close tickets instead of just acknowledging them. In sales, they qualify leads, update CRM records, and book meetings instead of just acknowledging an inquiry. In operations, they execute internal workflows instead of generating summaries that someone still has to act on.
“The question is not whether an AI agent can hold a conversation. The question is whether it can complete the task the conversation was about.”
When you evaluate a platform, evaluate it as an execution layer, not a communication layer. That mental model will guide every question you ask vendors and every test you run in a pilot.
The gap between demo performance and production performance is the most expensive problem in enterprise AI right now. Understanding why platforms fail helps you test for failure modes before they cost you money and customer trust.
The most common failure pattern is hallucinated answers caused by weak data grounding. A platform that relies on a general-purpose language model without tight retrieval from your actual knowledge base will invent answers when it does not know something. In a demo, the questions are curated and the data is clean. In production, customers ask things in unpredictable ways, your documentation has gaps, and the model fills those gaps with confident-sounding fiction.
The second failure pattern is integration shallowness. Many platforms offer integrations that are essentially read-only data display. They can show an agent the contents of a CRM record. They cannot update it, trigger a workflow in it, or write the outcome of a conversation back to it. The agent looks capable in a demo because someone is manually performing the actions the demo implies the agent can perform automatically.
The third failure pattern is the absence of guardrails. An AI agent making consequential decisions, such as issuing refunds, escalating contracts, or updating customer account details, needs explicit business logic that defines what it is and is not allowed to do. Platforms that rely solely on the model’s judgment introduce unpredictable risk. A well-designed platform lets you define rules, limits, approval requirements, and fallback behaviours declaratively, separate from the model.
The fourth failure pattern is poor human handoff. When an agent cannot resolve something, it must escalate gracefully. That means passing the full conversation context, the identified intent, and any data it retrieved to the human agent taking over. When handoff strips context, the customer repeats themselves, the human agent starts from scratch, and the efficiency gains from the AI are partially or fully erased.
Across hundreds of enterprise AI agent deployments, the platforms that work in production consistently perform well across these seven dimensions. Use this framework as your evaluation structure, and weight each area according to your specific use case.
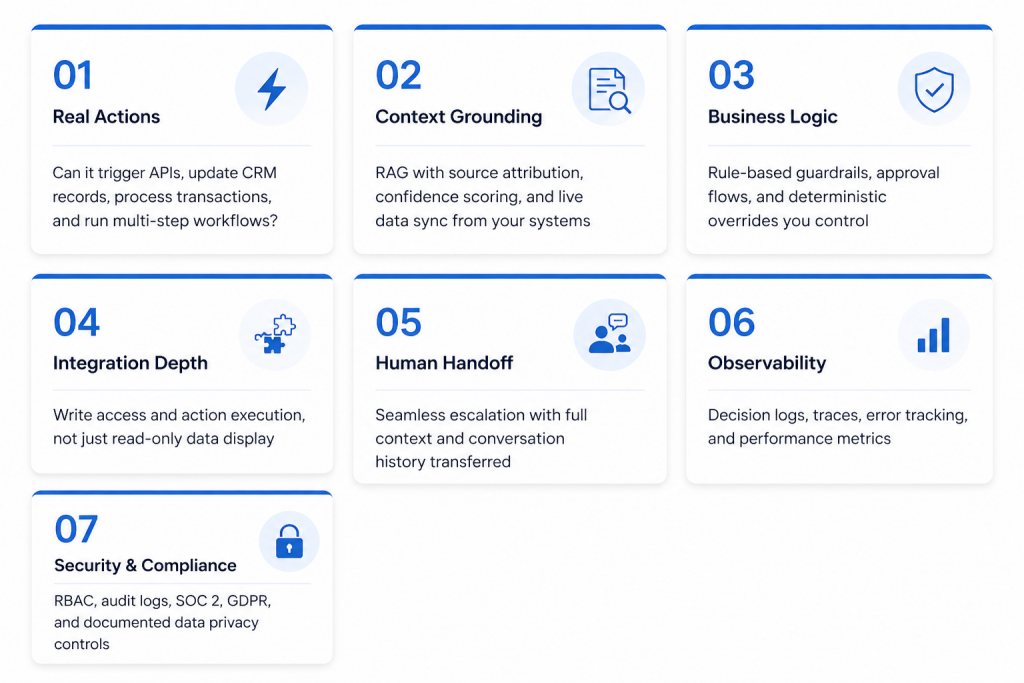
This is the most important criterion and the one most often glossed over in sales conversations. Ask every vendor the same direct question: what can the agent write, update, create, or delete in connected systems? If the answer is vague or redirects to what the agent can display, that is a critical red flag. You need a platform with a proper workflow builder that supports conditional logic and multi-step execution. You need it to be able to trigger external APIs, update records in your CRM, process refunds through your payment processor, and create or close tickets in your helpdesk without human intervention.
Test this specifically. Give the platform a task that requires three consecutive system actions and observe whether it completes them automatically or produces an output that a human then needs to act on.
An AI agent is only as accurate as the data it retrieves and the quality of its retrieval mechanism. Look for retrieval-augmented generation (RAG) that draws from your actual data sources, with source attribution so you know where every answer came from. Confidence scoring is important: a well-designed agent should know when it does not know something and should escalate or ask for clarification rather than guessing.
Before going live on any platform, build a golden question set of 50 to 100 questions drawn from your actual support history or sales conversations. Include questions you know the answer to, questions that are out of scope, and questions with subtle nuance. Run this set against the platform and score accuracy manually. This single test reveals more about production readiness than any demo.
Also check how frequently the platform syncs data from your sources. A platform that ingests your knowledge base once during onboarding and then goes stale is a liability as your products, policies, and pricing change.
AI agents make consequential decisions. You need to define the boundaries of those decisions explicitly. Evaluate whether the platform allows you to configure refund limits, escalation triggers, approval flows for high-value actions, and hard stops for situations the agent should never handle autonomously.
Look for deterministic workflow capabilities alongside the AI layer. The best platforms let you define rules that override the model. For example: if the refund amount exceeds a defined threshold, always escalate to a human regardless of what the model concludes. This is not a limitation of the technology; it is responsible deployment. Platforms that cannot support this level of control are not suitable for business-critical workflows.
There is a meaningful difference between a platform that lists a CRM in its integration catalogue and a platform that can actually write to your CRM. Go into every vendor conversation with a specific list of actions you need the agent to perform in each of your systems, and confirm support for each one individually.
At minimum, your AI agent needs deep connections to your CRM, your helpdesk, your payment processor, and your e-commerce platform if applicable. Deep means read and write access, the ability to trigger workflows, and the ability to create, update, and close records. Ask for a live demonstration of a write action in a test environment during your evaluation. If the vendor hesitates or cannot demonstrate it, assume it does not exist in production form.
An AI agent that cannot hand off gracefully is worse than no agent at all, because it produces a frustrating experience and then passes a frustrated customer to a human agent who has no context. Evaluate the escalation mechanism carefully. When the agent escalates, does the receiving agent see the full conversation? Do they see the intent the AI identified, the data it retrieved, and any actions it already took? Is there an internal notes layer that helps the human continue without starting over?
Also consider whether the platform supports collaborative workflows where AI assists human agents rather than replacing them. Some of the most effective deployments use AI to draft responses for human review, suggest next actions, or surface relevant data from the CRM during a live conversation. Evaluate both autonomous operation and assisted operation modes.
You cannot improve what you cannot see. After deployment, you need to know what the agent is doing, why it made specific decisions, and where it is failing. Ask vendors specifically about logging granularity. Can you trace every step of a multi-action workflow? Can you see which document chunk the agent retrieved to produce a given answer? Can you identify the conversations where the agent failed and understand why?
Performance dashboards matter too: resolution rate, escalation rate, accuracy over time, average handling time, and any degradation in model performance as your data changes. These should be built into the platform, not something you have to build yourself by querying an API.
Enterprise deployments have legal and regulatory obligations that most AI vendors are still catching up to. At minimum, ask for documentation of role-based access control, audit logging, data retention policies, and compliance certifications. SOC 2 Type II and GDPR compliance should be the baseline. If you operate in regulated industries such as healthcare, financial services, or legal, the requirements go further.
Understand specifically where your customer data goes. Is it used to train the vendor’s models? Is it shared with third parties? How long is it retained? What happens to it when you end the contract? Get these answers in writing, not in a sales call.
The seven criteria above apply universally. But each function has specific requirements that should shape how you weight the criteria and what you test for in a pilot.
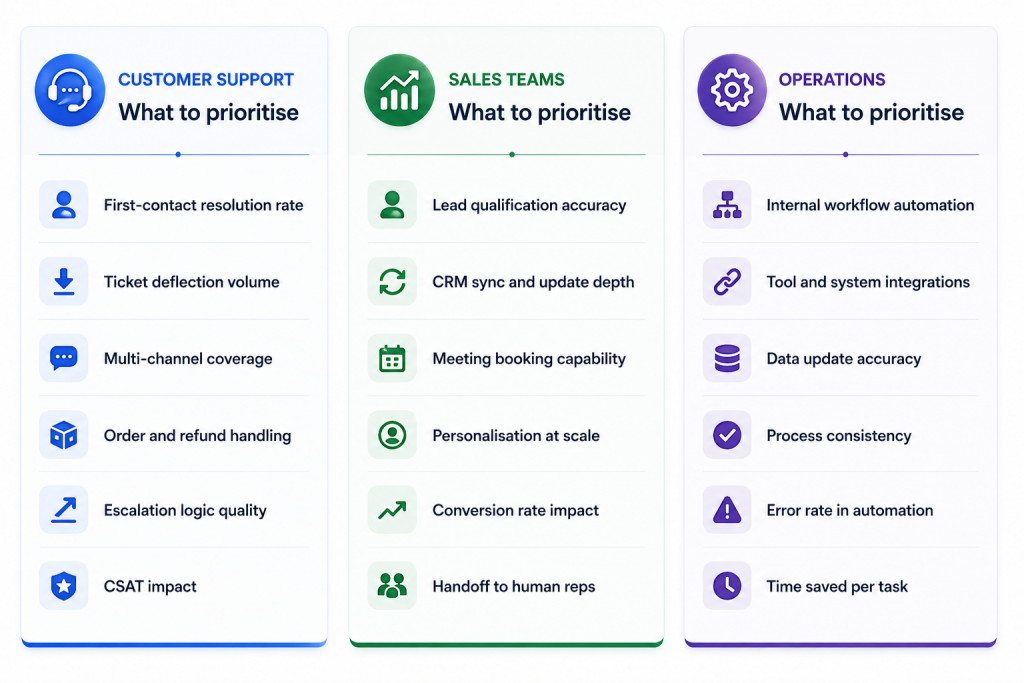
For customer support teams, the primary metric is first-contact resolution. Every conversation that ends without a human touching it is a measurable win. Focus your pilot on high-volume, rule-based request types: order status, refund requests, password resets, subscription changes. These are where AI agents produce the fastest return and the clearest signal of platform quality.
For sales teams, the quality of CRM integration is the most important variable. An agent that qualifies leads but cannot write those qualifications back to your CRM creates manual work that erodes the value proposition. Evaluate how the agent handles ambiguous or incomplete lead information, and test what happens when a prospect goes off-script from the typical qualification flow.
For operations teams, the focus is workflow completion rate and error rate. An agent that automates 80% of a process but introduces errors in 10% of runs may not represent a net positive. Set a clear accuracy threshold for automated workflows before deployment, and build monitoring that alerts on deviations from that threshold.
If you are currently running a chatbot and evaluating whether to upgrade to an AI agent platform, this comparison makes the decision criteria explicit.
| Capability | Traditional Chatbot | AI Agent Platform |
|---|---|---|
| Answers questions from knowledge base | Yes | Yes |
| Executes multi-step workflows | No | Yes |
| Writes to CRM or helpdesk | No | Yes (deep integrations) |
| Processes refunds or transactions | No | Yes (with guardrails) |
| Adapts to context mid-conversation | Limited | Yes |
| Escalates with full context | Rarely | Yes (if well-designed) |
| Decision-level observability | No | Yes |
| Configurable business logic | Rule-based only | Rule-based + AI judgment |
| Handles ambiguous queries | Poor | Strong |
The table above is not an argument that chatbots have no place. For very narrow, high-volume, low-complexity use cases, a simple rule-based chatbot can be faster and cheaper to deploy. But for any workflow that requires judgment, data access, or system actions, an AI agent platform is the more appropriate tool.
A structured evaluation process separates platforms that work in real conditions from those that only work in controlled ones. Follow these five steps in sequence.
These are the patterns that consistently indicate a platform will underperform in production. Treat any of them as a reason to probe deeper before progressing the evaluation.
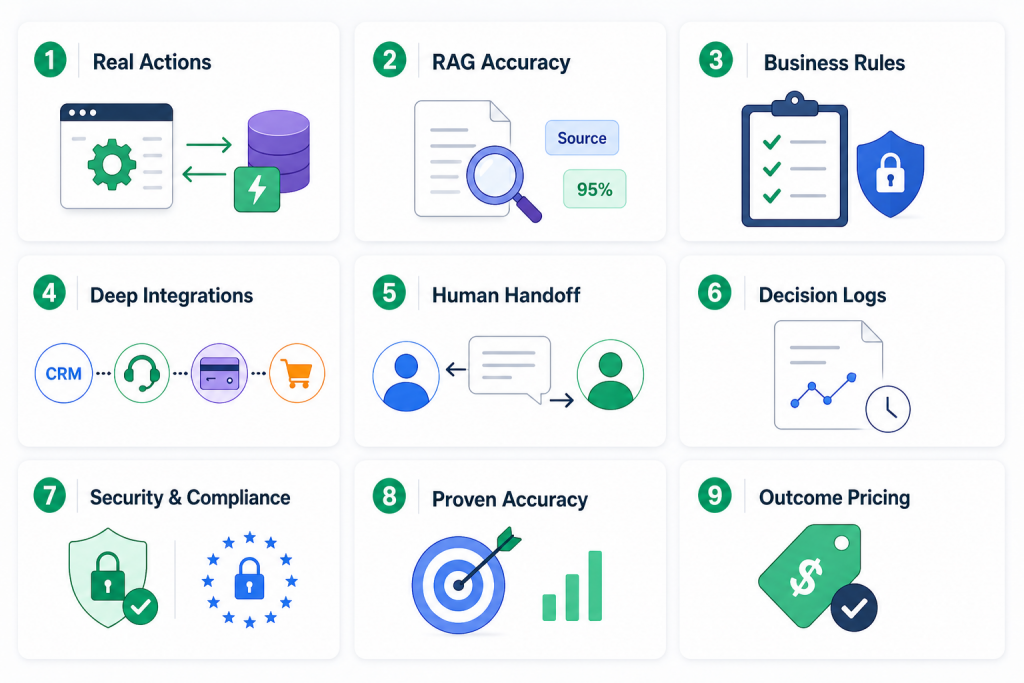
Use this checklist across your final two or three platform candidates. Every item should be verified through live testing or written vendor confirmation, not through a demo or a sales deck.
A chatbot retrieves and presents information in response to user queries. An AI agent takes action: it can query external systems, trigger multi-step workflows, update records in connected platforms, and complete tasks end to end without a human acting on its output. The practical difference is that an agent closes the loop rather than handing it back to a human.
Test it against a golden question set built from your real support or sales history, including edge cases and out-of-scope questions. Measure accuracy, resolution rate, and escalation rate on your actual data, not on a demo dataset. A platform that performs well on clean demo data and degrades significantly on your real data is not production-ready.
At minimum: your CRM, helpdesk, payment processor, and e-commerce platform, with write access and action-triggering capability in each. Read-only integrations are insufficient for most agent workflows. Confirm write access with a live demonstration in a test environment, not from a features list.
AI agents improve efficiency by resolving high-volume, rule-based queries without human involvement, reducing the ticket volume that reaches human agents. They handle refund requests, order status queries, subscription changes, and similar requests faster and at lower cost than a human agent, while freeing the support team to focus on complex, high-value interactions.
Not entirely, and that should not be the goal. AI agents perform well on high-volume, well-defined, lower-complexity workflows. Situations that require nuanced judgment, genuine empathy, legal or financial sensitivity, or escalated authority still need human involvement. The most effective deployments use AI to handle the high-volume routine work and humans to handle the high-value complex work.
For customer support: first-contact resolution rate and ticket deflection rate. For sales: qualified lead rate and conversion from AI-handled conversations. For operations: workflow completion rate and error rate in automated processes. Define your baseline on each metric before deployment so you have a clear before-and-after comparison.
A focused deployment covering one or two workflows with two or three integrations can go live in four to eight weeks. Complex enterprise deployments with deep integrations, custom workflow logic, compliance requirements, and multi-channel rollout typically take three to six months to reach full production. Beware vendors who promise enterprise-grade deployment in two weeks without qualification.
Industries with high support volumes, repetitive internal workflows, and rule-based decision making see the fastest returns: e-commerce, financial services, telecommunications, travel and hospitality, software and SaaS, and healthcare administration. The common thread is workflow predictability combined with high transaction volume.
Define explicit business logic and guardrails, configure action limits such as maximum refund amounts, require human approval for high-risk or high-value actions, and monitor decision logs continuously. Use confidence thresholds that trigger escalation rather than guessing when the agent is uncertain. The platform’s ability to support these controls is itself an evaluation criterion.
Run a golden question set covering standard queries, edge cases, and out-of-scope questions. Test multi-step action execution with live write access in a staging environment. Test escalation paths to confirm full context is passed to human agents. Test across all channels your customers will use. Set a minimum accuracy threshold and do not go live until the platform clears it.
Choosing an AI agent platform in 2026 is not fundamentally a technology decision. It is a reliability and execution decision. The platforms that succeed in production are not necessarily the ones with the most advanced underlying model. They are the ones designed to execute reliably in the messy, ambiguous, constantly changing conditions of real business operations.
The seven criteria in this blog, real actions, context grounding, business logic, integration depth, human handoff, observability, and security, provide a structure for cutting through demo theatre and testing what actually matters. Use them to ask sharper questions, design better pilots, and avoid the costly mistake of committing to a platform based on what it can do in a controlled environment.
The final principle is worth repeating: define your success metrics before you start evaluating. Know your current resolution rate, escalation rate, and average handling time. Set a threshold the platform must exceed during the pilot to earn deployment. Hold every vendor to that threshold. The ones that object to being measured on real outcomes are telling you something important about how confident they are in their product.
Focus on execution, not conversation. Test in realistic conditions before committing. And give yourself the option to walk away from a pilot that does not meet your bar. That discipline, applied consistently, is what separates organisations that successfully deploy AI agents from those that are still trying.

TL;DR AI agents are becoming part of everyday business operations across customer support, sales, onboarding, and internal workflows. In customer support, they are commonly used to answer questions, automate billing support, track orders, handle repetitive requests, collect information, route conversations, and assist human agents with context and actions. Some platforms focus mainly on conversational replies, […]

TL;DR YourGPT and Asana work best together when conversations can turn into structured tasks without manual handoff between support, ops, or project teams. You can connect them through Asana MCP, YourGPT AI Studio, or viaSocket, depending on whether you need agentic control, custom workflow logic, or a fast no-code setup. Start simple: use one clear […]

TL;DR Dental clinics often lose patients not due to treatment quality but because of slow or missed responses across calls, chats, and after-hours enquiries. AI agents help by responding instantly, collecting structured patient details, applying booking rules, and routing requests before they reach the front desk. Clinics that define clear workflows, set boundaries around clinical […]


TL;DR The best Shopify AI support agent is not defined by demos, but by how it performs under real customer scenarios with accurate, source-backed answers and clear boundaries. Reliable systems depend on strong knowledge grounding, retrieval of live store data, controlled permissions, and structured escalation, not just model quality or response fluency. Platforms like YourGPT […]

TL;DR AI improves speed, but real ROI appears when workflows no longer depend on a human queue and can be completed end to end. Autonomous agents shift cost structure by removing routine work from human flow, reducing cost per case, improving response time, and scaling capacity without linear hiring. Platforms like YourGPT help operationalize this […]

AI becomes far more useful when it can do more than answer questions. That is where autonomous AI agents stand apart. Instead of stopping at conversation, they can understand a goal, decide what needs to happen next, take action, and improve over time through real interactions. They are not fully independent. You still define the […]